Serendipity Is Not An Intent
- Edit
- Delete
- Tags
- Autopost

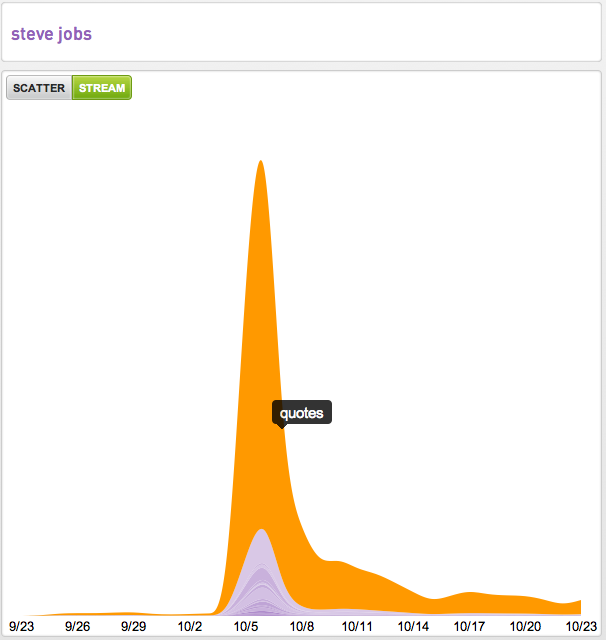
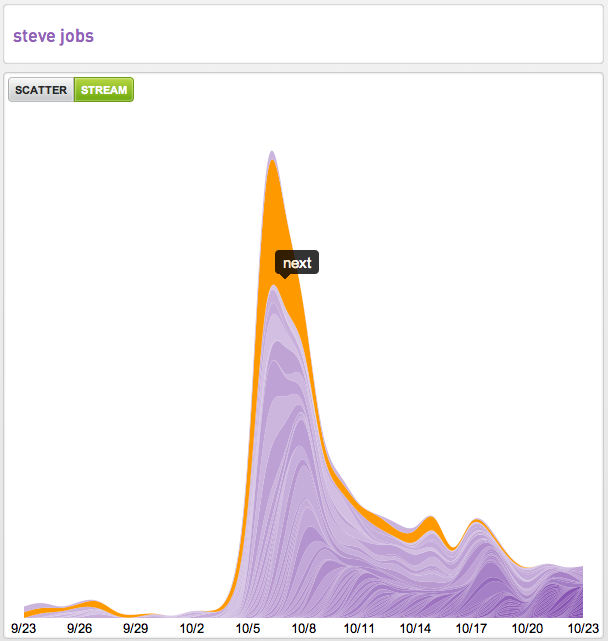
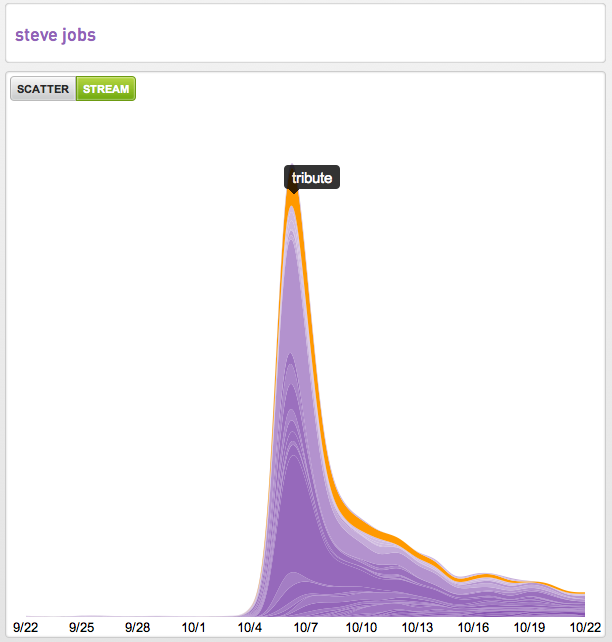
Wired had two amazing pieces on online advertising yesterday and while Felix Salmon’s piece The Future of Online Advertising could be Yieldbot’s manifesto it is the piece Can ‘Serendipity’ Be a Business Model? that deals more directly with our favorite topic, intent.
The piece discusses Jack Dorsey’s views on online advertising and where Twitter is going with it. I had a hard time connecting the dots.
“…all of that following, all of that interest expressed, is intent. It’s a signal that you like certain things,”
Following a user on Twitter is not any kind of intent other than the intent to get future messages from that account. If it’s a signal that you like certain things it’s a signal akin to the weak behavioral data gleaned from site visitations.
Webster’s dictionary describes intent as a “purpose” and a “state of mind with which an act is done.” Intent is about fulfilling a specific goal. Those goals fall into two classes, recovery and discovery.
Dorsey goes on:
When it (Google AdWords) first launched, Dorsey says, “people were somewhat resistant to having these ads in their search results. But I find, and Google has found, that it makes the search results better.”
At the dawn of AdWords I sat with many searchers studying their behavior on the Search Engine Results Pages. What I and others like Gord Hotchkiss who also studied searcher behavior at the time learned, was people were not as much resistant to Search Ads as they were oblivious to them. People did not know they were ads!
Search ads make the results better because they are pull. Your inputs into the system are what pull the ads. So how does this reconcile with the core of Twitters ad products that are promotions? Promos need scale to be effective. Promos are push. Precisely the opposite of Search where the smallest slices of inventory (exact match) produces the highest prices and best ROI.
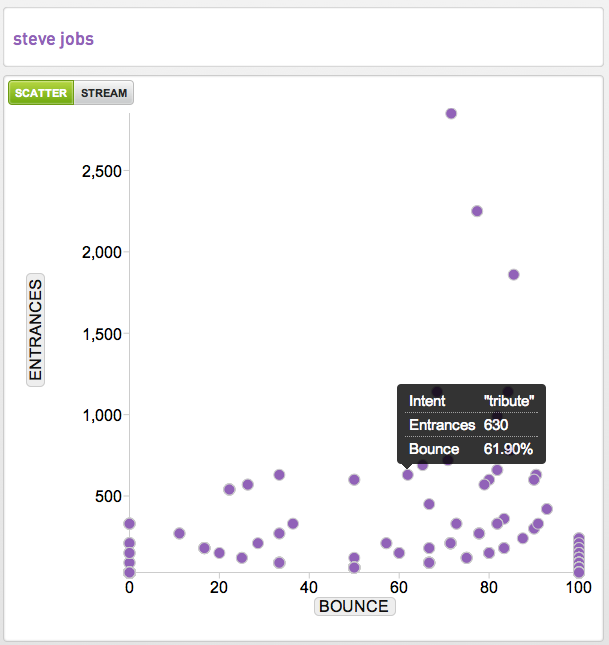
Twitter is the greatest discovery engine ever created on the web. But discovery can be and not be serendipitous. Sometimes, as Dorsey alludes to, you discover things you had no idea existed. More often, you discover things after you have intent around what you want to discover. This is an important differentiation for Twitter to consider because it’s a different algorithm.
Discovery intent is not an algo about “how do we introduce you to something that would otherwise be difficult for you to find, but something that you probably have a deep interest in?” There is no “introduce” and “probably” in the discovery intent algo. Most importantly, there is no “we.” It’s an algo about “how do you discover what you’re interested in.”
Discovering more about what you’re interested in has always been Twitter’s greatest strength. It leverages both user-defined inputs and the rich content streams where context and realtime matching can occur. Just like Search.
If Twitter wants to build a discovery system for advertising it should look like this.