Blog
Yieldbot's First Annual Super Bowl Intent Scorecard
Posted February 3rd, 2015 by Jonathan Mendez in intent, CTR
With the size of our platform now reaching 1 billion consumer sessions a month across our install base of premium publishers, we thought it made sense to take a look at the real-time intentions of consumers leading up to the Super Bowl. We focused on what everyone agrees is the best part of the game, food.

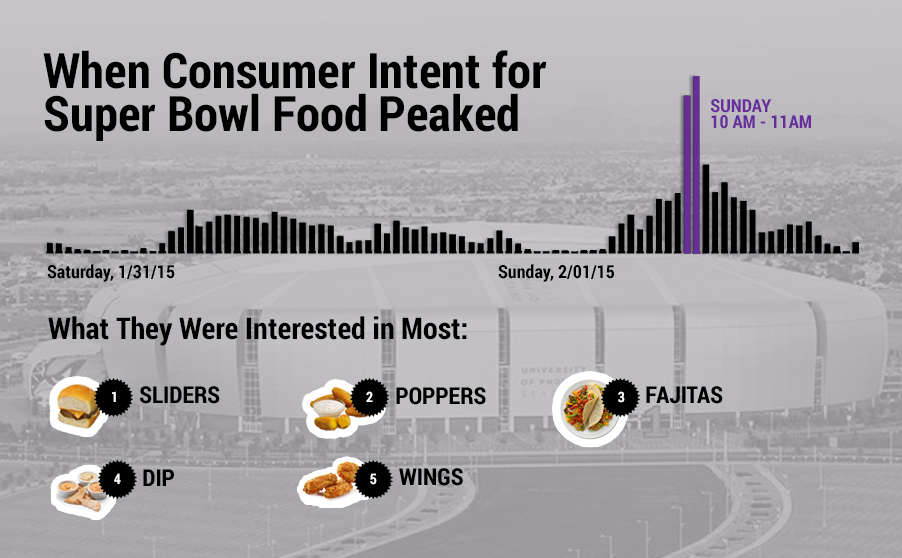


Of note, Yieldbot sold-out real-time intent for "Super Bowl" this year across 4 advertisers. Performance data shows they are glad they bought it.
If you are interested in buying other tent-pole or event related intent please contact [email protected]
Yieldbot 2014 Review by the Numbers
Posted December 22nd, 2014 by Jonathan Mendez in
It’s been an amazing 2014 at Yieldbot. Since one of our core values is being data driven, I am going to share some of our amazing internal data.
Everything we are and we accomplish starts with the team. In 2014 our team grew from 29 to 62 people. We opened 2 new offices (Chicago and Bentonville) and moved into 2 larger offices in Portland and New York City.
Yieldbot is webscale. In 2014 our technology collected and processed consumer activity on 8 billion consumer sessions across almost 400 premium publisher desktop and mobile websites. This equated to over 23 billion page-views of first party data and accounting for ad slots, over 50 billion real-time decisions. We do not measure “unique visitors” since we are a “cookieless” technology but on an aggregate level we likely have one of the largest footprints in digital advertising. Certainly we have one of the largest in premium content and the largest collection and use of first-party publisher data for monetization. Woohooo!
On the advertising side we ran over 1500 campaigns this year, many of which are “always-on.” Over 240,000 creative variations ran on Yieldbot in 2014 producing a platform wide CTR of .35%. It was not unusual to see desktop campaigns over .75% CTR or higher and mobile campaigns at 3% CTR. Reminder – these are display ads in IAB standard units.
For 2014 our top-line revenue grew 6.5X after growing 29x last year. Our gross profit grew over 14X this year after growing 46X last year. Our first 3 years of revenue compares almost identically to RocketFuel, who ended up being the #1 fastest growing technology company in the D&T; Fast 500 its first year of eligibility. It’s possible we are the fastest growing company in advertising technology right now and despite one-time costs associated with two office moves, December 2014 will be our first month of EBITDA profitability.
Our growth is fueled entirely by the performance of the media. We sell on a performance basis – 70% of our campaigns are run on a Cost-Per-Click (CPC) model. Our success is measured most on performance of the audiences we are helping drive to the marketer’s own sites and digital experiences. In that regard, we regularly beat the performance of paid search and crush other display technologies for our clients (ask [email protected] for the case studies). Also, 2014 was our first full year of offering mobile ads. 25% of our revenue in 2014 was from mobile. In Q4 it is 33% of our revenue. Mobile is growing fast.
Yieldbot will continue to be guided by the fundamental truth that we can never be successful unless our publishers are. Our commitment to publishers and more specifically to the people that consume their media must be forefront in our minds. Everything flows from that.
2014 was a banner year for our publishers. For our largest publishing partner, a media titan, we are their single largest partners - digital or print. They will generate over $6M from Yieldbot for 2014. Many other publishers are in the million-dollar club and many others will be soon as quarter-over-quarter revenue to publishers is growing fast.
A large part of our publisher success is that we delivered CPMs 2-4X what publishers are getting from ad exchanges or other partners such as SSPs. Since the backbone of our tech is machine learning (or as I like to say machine “earning”) our most successful publishers are the ones our technology has been on the longest. They are getting CPM in the $5-$10 range. This is on desktop and mobile. Maybe our best story of the year is a large site with 22M unique visitors a month that had been a huge Google partner but is now getting RPM from Yieldbot as high as 11X Google and for the first time ever has a partner delivering more total monthly revenue than Google. Cha-ching!
One other amazing thing happened on the publisher side of our business this year. Our success with their first-party data lead to publishers asking to use our technology to serve their own direct-sold campaigns and creation of a service model for Yieldbot. These publishers, some of the largest on the web, are now delivering CTR performance 5X what they were delivering running campaigns with data from their DMP and using their Ad Server waterfall to decision. In addition, they are delivering back-end metrics that allow them to compete for budgets going to Facebook and Google. Ask [email protected] for the case studies.
We made other incredible advances with our technology this year as well. We increased our lead in understanding real-time consumer activity with major efforts around real-time data streaming and the quality of our intent scoring and optimization decisions. We also helped a number of our publishers with issues around fraudulent traffic (at no charge) since we have our own systems to validate visitors. As a performance technology the onus/cost is on us to ensure we are serving to quality traffic.
We did it all in a fully transparent manner, building trust with our direct relationships at the agencies and with publishers. If publishers want to know their highest RPM pages by referrer source for Monday mornings we are happy that we can provide that data. If advertisers want to know what creative headline drove the highest conversion rate in the afternoon we are happy that we can provide that data. What we’re most proud of is that not only have we built a business that can provide this deep level of learning, but also by the time we have that data it is already being acted upon by our tech to improve business results.
2014 was the year Yieldbot got on the map and truly started blowing people’s minds with our technology and our results. For our company it was clearly “the end of the beginning.” Next year, it will not be enough to simply outperform our competitors. We are focused on transforming an entire industry so that advertisers, publishers and consumers all receive the benefits of relevance. Namely, increasing the value of digital media for every participant. We are excited for 2015 and thankful to everyone that helped us get this far in our journey.
Rise of the Intelligent Publisher
Posted November 10th, 2014 by Jonathan Mendez in Media, CPC, Performance , Publishers, Data, Analytics, First Party, real-time
Last week was yet another digital advertising event week in New York City – ad:tech and surrounding events. Everyone involved was talking about all the great advances in advertising technology happening right now. Nobody was talking about the advances in publisher technology. Frankly, there isn’t much to talk about. Except that there is.
A certain group of publishers have advanced light years ahead of the current discourse. Advanced beyond the idea of programmatic efficiency. Advanced beyond the idea of creating segments by managing cookies. Advanced far beyond unactionable analytic reports related to viewability. These publishers, many of whom are the most revered names in media, have deployed machine learning and artificial intelligence in their media. They have moved beyond optimizing delivery of impressions to predictive algorithms optimizing ad server decisions in real-time against the performance of their media.
The movement towards publishers understanding and optimizing their media is one of retaining the value of ownership. It may seem obvious that publishers own their media but they don’t really. In reality when the buyer is the one that is optimizing the performance of that media and keeping the learning – even using that learning as leverage in what they are buying – the value in ownership, in fact the entire value of a publishing business, is called into question.
The smartest and most forward thinking publishers understand the stakes. We are entering a world where all media is performance media. Brands are getting smarter about attribution and measurement. They are getting smarter about marketing mix models and seeing the value in digital over other channels. They are gaining insight into how digital influences purchase. In this new world the imperative of publishers to be as knowledgeable about their media as brands is not about competitive intelligence. It is about better performance for these very brands – their customers!
Publishers will not survive in a world where they do not know when, why, where, how and someone is walking into their store. They will not survive if they do not know what customers are buying and how much they are paying. No business could survive that lack of data and intelligence. In fact, no customer really wants that type of store either. Customers want to buy products that serve their intended purpose. Customers want sellers to understand — even predict — what they will be interested in. Customer experience extends to buying media the same as buying anything else. This means marketer performance.
Publishers are ultimately responsible for the performance of their media and the happiness of their customers. Yet, many never think about it or feel helpless to do anything about it. They are the ones that will not make the transition to the performance media economy.
Like all intelligent systems at the core this is about data. Vincent Cerf famously said Google didn’t have better algorithms, they just had more data. The reality is no one has more data than publishers. Each landing on the site, each pageview by a consumer has well over a hundred dimensions of data. That data is fundamental to the structure of the web – it is linked data – and the serialization of it through each site session creates exponentially more of it. Unlike cookie data that does not scale this data is web scale. And it can be captured, organized and activated in real-time.
The data is a window into the consumer mindset and journey. Importantly for publishers it is an explicit first-party value exchange between the publisher and the consumer. It is an exchange of intent for content, of mindset for media. It is what brands want more than anything else. The moment, the zeitgeist, the exact time and place a consumer is considering, researching, comparing, evaluating, learning, and discovering what and where to buy. It is the single most valuable moment in media. It is right time, right place, right message. It is uniquely digital, uniquely first-party and owned solely by the publisher. It is a gold mine that Facebook and Google recognize and they have focused their recent publisher-side initiatives on capturing from publishers either unsuspecting or incapable of extracting the value themselves.
As publishers begin to understand these moments themselves, activate them for marketers and optimize the performance of the media against them, an amazing thing happens. The overall value of the media increases. It increases because of intelligence. It increases because of performance. Most important, it increases because of value being delivered to consumers. It also opens up new budgets. Over time, these systems will get smarter. With more data, publishers can even begin to sell based on performance thereby eliminating a host of issues around impression based buying and increasing overall RPM by orders of magnitude with higher effective CPMs and smarter, more efficient allocations of impressions.
Unfortunately for the hungry advertising trade publications you will not hear these most advanced publishers talking on panels about this or writing blog posts. Does Google talk about Quality Score? Does Facebook talk about News Feed? You will not hear industry trade groups arguing for publishers to sell performance to their customers either. In fact not one panel all of last week discussed first-party data created by the publisher.
Thankfully there is no hype related to this. Only performance. The people who need to know, know. As much as I’d like to share the names of every one of those publishers and agencies with you, more so I want to honor their competitive advantage in the marketplace.
The best publishers have the best content. The best content delivers the best consumers. The best consumers deliver the best performance. This is not new. The rise of the intelligent publisher in collecting, organizing, machine learning, activating and algorithmically optimizing this first-party data stream in real-time is. It’s the most groundbreaking thing in media happening right now and will be for some time because it has swung the data advantage pendulum to the publishers for the first time since data has mattered in digital media.
TF-IDF using flambo
Posted July 22nd, 2014 by Muslim Baig in Clojure, Data, flambo, Analytics
flambo is a Clojure DSL for Spark created by the data team at Yieldbot. It allows you to create and manipulate Spark data structures using idiomatic Clojure. The following tutorial demonstrates typical flambo API usage and facilities by implementing the classic tf-idf algorithm.
The complete runnable file of the code presented in this tutorial is located under the flambo.example.tfidf namespace, under the flambo /test/flambo/example directory. We recommend you download flambo and follow along in your REPL.
What is tf-idf?
TF-IDF (term frequency-inverse document frequency) is a way to score the importance of terms in a document based on how frequently they appear across a collection of documents (corpus). The tf-idf weight of a term in a document is the product of its tf weight:
tf(t, d) = (number of times term t appears in document d) / (total number of terms in document d)
and its idf weight:
idf(t) = ln((total number of documents in corpus) / (1 + (number of documents with term t)))
Example Application Walkthrough
First, let's start the REPL and load the namespaces we'll need to implement our app:
lein repl user=> (require '[flambo.api :as f]) user=> (require '[flambo.conf :as conf])
The flambo api and conf namespaces contain functions to access the Spark API and to create and modify Spark configuration objects, respectively.
Initializing Spark
flambo applications require a SparkContext object which tells Spark how to access a cluster. The SparkContext object requires a SparkConf object that encapsulates information about the application. We first build a spark configuration, c, then pass it to the flambo spark-context function which returns the requisite context object, sc:
user=> (def c (-> (conf/spark-conf)
(conf/master master)
(conf/app-name "tfidf")
(conf/set "spark.akka.timeout" "300")
(conf/set conf)
(conf/set-executor-env env)))
user=> (def sc (f/spark-context c))
master is a special "local" string that tells Spark to run our app in local mode. master can be a Spark, Mesos or YARN cluster URL, or any one of the special strings to run in local mode (see README.md for formatting details).
The app-name flambo function is used to set the name of our application.
As with most distributed computing systems, Spark has a myriad of properties that control most application settings. With flambo you can either set these properties directly on a SparkConf object, e.g., (conf/set "spark.akka.timeout" "300"), or via a Clojure map, (conf/set conf). We set an empty map, (def conf {}), for illustration.
Similarly, we set the executor runtime environment properties either directly via key/value strings or by passing a Clojure map of key/value strings. conf/set-executor-env handles both.
Computing TF-IDF
Our example will use the following corpus:
user=> (def documents [["doc1" "Four score and seven years ago our fathers brought forth on this continent a new nation"] ["doc2" "conceived in Liberty and dedicated to the proposition that all men are created equal"] ["doc3" "Now we are engaged in a great civil war testing whether that nation or any nation so"] ["doc4" "conceived and so dedicated can long endure We are met on a great battlefield of that war"]])
where doc# is a unique document id.
We use the corpus and spark context to create a Spark resilient distributed dataset (RDD). There are two ways to create RDDs in flambo:
- parallelizing an existing Clojure collection, as we'll do now:
user=> (def doc-data (f/parallelize sc documents))
- reading a dataset from an external storage system
We are now ready to start applying actions and transformations to our RDD; this is where flambo truly shines (or rather burns bright). It utilizes the powerful abstractions available in Clojure to reason about data. You can use Clojure constructs such as the threading macro -> to chain sequences of operations and transformations.
Term Frequency
To compute the term frequencies, we need a dictionary of the terms in each document filtered by a set of stopwords. We pass the RDD, doc-data, of [doc-id content] tuples to the flambo flat-map transformation to get a new, stopword filtered RDD of [doc-id term term-frequency doc-terms-count] tuples. This is the dictionary for our corpus.
flat-map transforms the source RDD by passing each tuple through a function. It is similar to map, but the output is a collection of 0 or more items which is then flattened. We use the flambo named function macro flambo.api/defsparkfn to define our Clojure function gen-docid-term-tuples:
user=> (f/defsparkfn gen-docid-term-tuples [doc-tuple]
(let [[doc-id content] doc-tuple
terms (filter #(not (contains? stopwords %))
(clojure.string/split content #" "))
doc-terms-count (count terms)
term-frequencies (frequencies terms)]
(map (fn [term] [doc-id term (term-frequencies term) doc-terms-count])
(distinct terms))))
user=> (def doc-term-seq (-> doc-data
(f/flat-map gen-docid-term-tuples)
f/cache))
Notice how we use pure Clojure in our Spark function definition to operate on and transform input parameters. We're able to filter stopwords, determine the number of terms per document and the term-frequencies for each document, all from within Clojure. Once the Spark function returns, flat-map serializes the results back to an RDD for the next action/transformation.
This is flambo's raison d'être. It handles all of the underlying serializations to/from the various Spark Java types, so you only need to define the sequence of operations you would like to perform on your data. That's powerful.
Having constructed our dictionary we f/cache (or persist) the dataset in memory for future actions.
Recall term-frequency is defined as a function of the document id and term, tf(document, term). At this point we have an RDD of raw term frequencies, but we need normalized term frequencies. We use the flambo inline anonymous function macro, f/fn, to define an anonymous Clojure function to normalize the frequencies and map our doc-term-seq RDD of [doc-id term term-freq doc-terms-count] tuples to an RDD of key/value, [term [doc-id tf]], tuples. This new tuple format of the term-frequency RDD will be later used to join the inverse-document-frequency RDD and compute the final tf-idf weights.
user=> (def tf-by-doc (-> doc-term-seq
(f/map (f/fn [[doc-id term term-freq doc-terms-count]]
[term [doc-id (double (/ term-freq doc-terms-count))]]))
f/cache)
Notice again how we were easily able to use the Clojure destructuring facilities on the arguments of our inline function to name parameters.
As before, we cache the results for future actions.
Inverse Document Frequency
In order to compute the inverse document frequencies, we need the total number of documents:
user=> (def num-docs (f/count doc-data))
and the number of documents that contain each term. The following step maps over the distinct [doc-id term term-freq doc-terms-count] tuples to count the documents associated with each term. This is combined with the total document count to get an RDD of [term idf] tuples:
user=> (defn calc-idf [doc-count]
(f/fn [[term tuple-seq]]
(let [df (count tuple-seq)]
[term (Math/log (/ doc-count (+ 1.0 df)))])))
user=> (def idf-by-term (-> doc-term-seq
(f/group-by (f/fn [[_ term _ _]] term))
(f/map (calc-idf num-docs))
f/cache)
TF-IDF
Now that we have both a term-frequency RDD of [term [doc-id tf]] tuples and an inverse-document-frequency RDD of [term idf] tuples, we perform the aforementioned join on the "terms" producing a new RDD of [term [[doc-id tf] idf]] tuples. Then, we map an inline Spark function to compute the tf-idf weight of each term per document returning our final RDD of [doc-id term tf-idf] tuples:
user=> (def tfidf-by-term (-> (f/join tf-by-doc idf-by-term)
(f/map (f/fn [[term [[doc-id tf] idf]]]
[doc-id term (* tf idf)]))
f/cache)
We again cache the RDD for future actions.
Finally, to see the output of our example application we collect all the elements of our tf-idf RDD as a Clojure array, sort them by tf-idf weight, and for illustration print the top 10 to standard out:
user=> (->> tfidf-by-term
f/collect
((partial sort-by last >))
(take 10)
clojure.pprint/pprint)
(["doc2" "created" 0.09902102579427793]
["doc2" "men" 0.09902102579427793]
["doc2" "Liberty" 0.09902102579427793]
["doc2" "proposition" 0.09902102579427793]
["doc2" "equal" 0.09902102579427793]
["doc3" "civil" 0.07701635339554948]
["doc3" "Now" 0.07701635339554948]
["doc3" "testing" 0.07701635339554948]
["doc3" "engaged" 0.07701635339554948]
["doc3" "whether" 0.07701635339554948])
user=>
You can also save the results to a text file via the flambo save-as-text-file function, or an HDFS sequence file via save-as-sequence-file, but we'll leave those APIs for you to explore.
Conclusion
And that's it, we're done! We hope you found this tutorial of the flambo API useful and informative.
flambo is being actively improved, so you can expect more features as Spark continues to grow and we continue to support it. We'd love to hear your feedback on flambo.
Marceline's Instruments
Posted June 25th, 2014 by Homer Strong in Clojure, Data, Storm, Analytics
Last December Yieldbot open-sourced Marceline, our Clojure DSL for Storm’s Trident framework. We are excited to release our first major update to Marceline, version 0.2.0.
The primary additions in this release are wrappers for Storm’s built-in metrics system. Storm’s metrics API allows topologies to record and emit metrics. Read more on Storm metrics in the official documentation. We run production topologies instrumented with Marceline metrics and have found it to be stable; YMMV! Please file issues on GitHub if you encounter bugs or have ideas for how Marceline could be improved. See the Metrics section of the README for usage. Also note that Marceline’s metrics can be useful for any Clojure Storm topologies, either with vanilla Storm or Trident.
Marceline’s exposure of Storm metrics has been very useful for monitoring the behavior of Yieldbot’s topologies. Friction around instrumentation has been greatly reduced. Code smells are down. Metrics now entail fewer lines of code and less duplication. An additional architectural benefit is that dependencies on external services can be isolated to individual topology components. It is painless to add typical metrics while maintaining enough flexibility for custom metrics when necessary. We have designed Marceline’s metrics specifically with the goal to leverage Storm’s metrics API unobtrusively.
As Yieldbot’s backend scales it is increasingly crucial to monitor topologies. Simultaneously, new features require iterations on what quantities are monitored. While topology metrics are primarily interesting to developers, these metrics are often directly related to data-driven business concerns. Several of Yieldbot’s Key Performance Indicators (KPIs) are powered by Storm and Marceline, so the availability of a fantastic metrics API translates to greater transparency within the organization.
If you’re interested in such data engineering topics as this, check out some of the exciting careers at Yieldbot!
-- @strongh
Browse by Tags
Yieldbot In the News
RTB’s Fatal Flaw: It’s too slow
From Digiday posted September 23rd, 2014 in Company News
Yieldbot Hands Publishers A New Way to Leverage Their First-Party Data
From Ad Exchanger posted September 23rd, 2014 in Company News
Yieldbot Raises $18 Million to Advance Search-Style Display Buying
From AdAge posted September 23rd, 2014 in Company News
Follow Us
Yieldbot In the News
RTB’s Fatal Flaw: It’s too slow
From Digiday posted September 23rd, 2014 in Company News
I have some bad news for real-time bidding. The Web is getting faster, and RTB is about to be left behind. Now, 120 milliseconds is becoming too long to make the necessary computations prior to page load that many of today’s systems have been built around.
Visit Site
Yieldbot Hands Publishers A New Way to Leverage Their First-Party Data

From Ad Exchanger posted September 23rd, 2014 in Company News
Yieldbot, whose technology looks at a user’s clickstream and search data in order to determine likeliness to buy, is extending its business to give publishers a new way to monetize their first-party data.
Visit Site
Yieldbot Raises $18 Million to Advance Search-Style Display Buying
From AdAge posted September 23rd, 2014 in Company News
Yieldbot, a New York based ad-tech company that lets advertisers buy display ads via search-style keywords, has raised a $18 million series B round of funding
Visit Site
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
The most amazing thing about the Federal Trade Commission’s workshop about native advertising Wednesday morning is that it happened at all. As Yieldbot CEO Jonathan Mendez noted...
Visit Site
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Publishers in women’s programming verticals such as food and recipes, home and garden, style and health and wellness have found a deep, high volume source of referral traffic from Pinterest.
Visit Site
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Pinterest may have quickly arrived as a major source of traffic to many websites, but those visitors may click on the ads they see there less often than others.
Visit Site
From Our Blog
Yieldbot's First Annual Super Bowl Intent Scorecard
Connect With Us
Where to Find Us
New York City
149 5th Ave.
Third Floor
New York, NY
10010
Boston
1 Clock Tower Place
Suite 330
Maynard, MA
01754
Portland
1033 SE Main St.
Suite #4
Portland, Oregon
97202