Blog
The Databases of Yieldbot
Posted September 21st, 2012 by admin in Insight
Last night we held our first Yieldbot Tech Talks meetup, where we went into detail about the technologies that we use for data handling and storage in various parts of our platform.
MongoDB excelled as an initial choice of a flexible database that allowed for just getting stuff done and focusing on the million other things that need to be thought about when iterating around an initial idea. As our needs evolved in various areas of data we then transitioned to the best technologies and approaches for those specific cases. We now use (in addition to MongoDB) redis, ElephantDB, HBase, and our own DB technology called HeroDB that we use for configuration data.
Here are the slides:
Yieldbot Tech Talk, Sept 20, 2012 from yieldbot
Like how we roll? We’re hiring! Find out more.
Doing Production Deploys with git
Posted September 6th, 2012 by admin in Insight
At Yieldbot we follow a schedule of daily (or more) releases per day, coordinated by Chef with git smack in the middle.
To start, like many we’re happy users of GitHub for coordinating our code repositories across our development team, and our use is pretty straightforward for that. Developers change code, pull down everyone else’s changes, merge, push up their changes, etc. It’s like a “hub” for our “git” usage (whoah!).
git != GitHub
It’s important to remember though that GitHub, while making a certain usage pattern convenient, is not synonymous with “git”; a fact that we make use of heavily.
Using git’s ability to set up multiple remotes or have default remotes not up on GitHub provides for some powerful options in how code can be moved around and managed. Something we take advantage of every day both in production (which we’ll talk about in this post) and in our development environments (covered in a later blog post).
git + Chef == a tasty treat
For this post the important thing to understand about Chef is that we have a central Chef server that serves as the coordination point for deployment. The servers throughout the platform run chef-client to find out from the Chef server what they should be running and Chef and its cookbooks make it so.
To control what version of our code is deployed we have a git repo on the Chef server cloned from the repo up on GitHub. The core of our deploy procedure is to pull the latest on “master” branch from GitHub into the repo on Chef server, tag it with the name of the release, and also tag it with a special tag that moves called “production” (ie. “git tag -f production”).
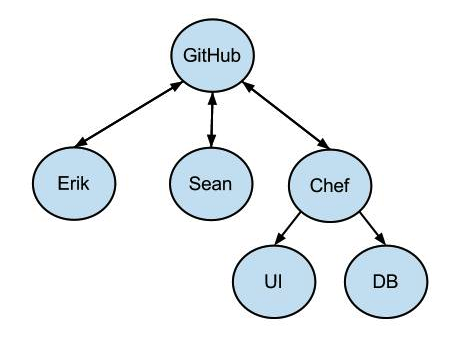
Using a Chef recipe, each of the servers in our platform are also set up with the git repo but with the repo on the Chef server as their origin. During a deploy these repos fetch from the Chef server remote and sync to the “production” tag.
Once the repo on Chef server set up with the “production” tag in place where desired for the deploy, the actual deploy is triggered by poking the servers in the platform to run chef-client.
Note in the diagram above that in addition to the usual usage of git between developers Erik and Sean, the Chef server is also set up with GitHub as the remote. Below the Chef server are two examples of servers (UI and DB) that are set up with the Chef server as their remote. Note that UI and DB really only pull from the Chef server repo. The Chef server in turn mostly pulls from GitHub, although it does push back to GitHub the state of tags as manipulated during the deploy.
Features/BenefitsYou can easily change the location of the “production” tag on the Chef server repo and then resync the servers in the platform to deploy any level of code desired.
During a deploy, our servers are not dependent on contacting GitHub. To start a deploy we sync the Chef server’s repo with GitHub, but we could just as easily push to the Chef server’s repo from somewhere else, or even add a different remote to the Chef server’s repo to pull from another location instead.
If any changes are made to a system to make it deviate from what was last deployed, a “git diff” in the repo on that server can expose exactly what those changes were made on that specific server (if you’ve worked with deployed code before you know this concept is huge).
Next UpIn a follow-on blog post we’ll cover some more advanced uses of multiple git remotes that we leverage in our development environments.
What If (First Party Data Told You) Everything You Thought About Online Advertising is Wrong
Posted August 20th, 2012 by admin in
Now that we have a few months and over a billion ad match decisions on referrer data at Yieldbot we’re seeing some very interesting performance results. Segmenting performance metrics by referrer source has always been 101 for e-commerce but amazingly has rarely if ever been capably measured/optimized for web publisher monetization. However, referrers are very important to Yieldbot because referrer data is a primary data source in our intent decisioning algos.
We look at referrers in two ways at Yieldbot. We look at session referrer – meaning the referring source of the visitor session on publisher – both domain and URL level. Also we look at the match referrer – meaning the referring source – both domain and URL level - to the actual ad match impression.
Session referrers are always external domains. They can be bookmarks, emails, search, social and every other way a person can get to a website.
Match referrers can be both external (for every ad match on a site landing) and internal URLs (for every ad match during a site session).
What we’ll share about CTR of internal match referrers is that they are the highest performing. CTR in-session — user page view 2 and above — as a whole performs 2X better than ad match impressions on landing. This counters much of what you hear in ad tech circles and more closely mirrors Search where CTR increases with query refinement.
It’s also a great validation of our thesis that the serialization of session data can operate ad match rules with higher performance than a single page level rule. Again, this looks like e-Commerce to a great extent because click path data is delivering the rule and gaining decision intelligence with each additional user click in session.
What we’ll share about CTR performance on external match referrer data for Top 10 ranking for the past 3 months. Everyone loves Top 10 lists, right?
Top 10: Yieldbot CTR by External Match Referrer
1.Direct
2.Facebook
3.Outbrain
4.Bing
5.Yahoo
6.Ask
7.Comcast
8.Google
9.Aol.com
10.Pinterest
Much of what we see here runs counter to the prevailing wisdom about online advertising.
The idea that Publisher Direct traffic does not click on ads. The idea that Facebook traffic has no commercial value. The idea that Search traffic has the most obvious intent. The idea that Pinterest is the future of the commercial web. So far, our data points that all those assumptions need to be called into question.
From day 1 at Yieldbot we’ve been about breaking new ground by using first party publisher analytics to understand and redefine the relationship of visitors and monetization. We’re incredibly excited that these early results are so fascinating and we’re digging deeper. It’s possible everything thought known about online advertising was wrong. It’s likely online advertising has never been done right for publishers and advertisers at the site level. The time’s they are a changing.
The Missing “Why” for Publishers
Posted August 5th, 2012 by admin in Insight
During my time at The Wall Street Journal Digital Network, one problem we did not have, at least in aggregate, was traffic. The Network was one of the largest players in the business/finance category in both NNR & comScore, growing year over year. And the page views per visit for subscribers, not to mention engagement, were some of the highest…if not THE highest…of any other business property. Those readers who paid for content got their money’s worth!
Sideways traffic - that driven from search, portals, aggregators, et al. - was a different story. While it helped drive unique user growth, the traffic was mostly in and out. After landing on an article, we were lucky to see a user turn an additional page before leaving the site. We tried several methods to address this: we employed technologies to surface related or recommended content based on the content of the page, general subject matter, even social sharing. We made assumptions based on referral source and surfaced headlines accordingly – those who came from the Yahoo homepage or Facebook must be interested in general, non-business articles. If they came from a Y! Finance quote page they must be interested in articles about the company ticker they were looking up. And if they came from Drudge they must be looking for Opinion Page content. But despite these efforts, we never managed to significantly move the needle on those page views per visitor numbers.
That is because we never really understood WHY a user came to a site.
These were simply inferences, and though we tested surfacing content based on those inferences, we never managed to significantly move the page view per users numbers. Again, because we never understood “why” the user was coming to our site.
Yieldbot’s core value proposition is just that – looking at a variety of queues that inform what drives a user into a site, all in-session, and distilling that intent into keywords that can then be used as a real-time match rule to improve monetization. We drive performance for advertisers and we drive revenue for publishers. But we also generate understanding.
When we distill intent we see how many pages a users turns when they come to the site looking for, say, “ETF.” We see the percentage of time users who come into a site with the intent of “ETF” return to the site. And we see how often that intent causes users to leave or “bounce”. Beyond immediate monetization improvements due to better ad matching this data be used by a publisher to understand traffic trends and make programming and promotion decisions.
Let’s say site XYZ.com gets 10M UU’s per month. Any good SEO person will tell you that the sweet spot for search traffic is about 20%. Any less and you’re not optimized. Much more and you’re one Google algorithm tweak away from falling off a traffic cliff. The other 8M users are coming directly or thru other “sideway” means such as partner sites, portals, social media, etc. If that accounts for 20% of total traffic, you’re doing well – give those biz & audience development folks raises! But more than likely that traffic is driving 2 or less PV’s/visit (4M PVs/month). By understanding why those users come to your site, surfacing content that is of interest to them and getting them to turn an additional page, that’s now 6M PVs per month or an increase of 30%. If you’re a subscription-based site or have a newsletter product, think of applying that understanding to help drive subs!
At Yieldbot, we’re just getting started at generating value for our publisher partners. We distill intent into keywords and match them to ads in real-time, at the exact time a reader is most open to them. And the same can be done for content. After all, for publishers it is successful marriage of page content, visitor intent and the relevant advertisments that improve your business. Any of these three pieces working in a silo lower your value.
More to come!
Proving Display Can Perform Better than Search
Posted August 4th, 2012 by admin in Insight

What more can we say here. The numbers speak for themselves.
Yieldbot Conversion Rate: 35.59% G2
Yieldbot Conversion Rate: 26.04% G3
Google CPC Conversion Rate: 29.23% G2
Google CPC Conversion Rate: 20.65% G3
Google Organic Conversion Rate: 7.81% G2
Google Organic Conversion Rate: 6.10% G3
That’s a 26% higher conversion rate vs. Google Paid Search for Goal 3 and 326% higher conversion rate than Google Organic Search.
This is the first two weeks of data for the campaign. As hard as it is to believe these numbers are before any optimization has taken place.
These are IAB standard 300 x 250 and 728 x 90 units. But the realtime decisioning on the ad call is anything but standard. In fact, we believe these results bear out that Yieldbot has redefined relevance in display and created a new advertising channel in the process. A channel unlike any other.
We’ve worked for over two years to build Yieldbot on the thesis that first party publisher data to harvest intent and realtime decisioning to match against it would deliver performance that would rival Search. Even we didn’t think one of our early campaigns would out perform it. It’s great news for marketers and publishers. For us, the best news is that we’re just getting started.
Browse by Tags
Yieldbot In the News
RTB’s Fatal Flaw: It’s too slow
From Digiday posted September 23rd, 2014 in Company News
Yieldbot Hands Publishers A New Way to Leverage Their First-Party Data
From Ad Exchanger posted September 23rd, 2014 in Company News
Yieldbot Raises $18 Million to Advance Search-Style Display Buying
From AdAge posted September 23rd, 2014 in Company News
Follow Us
Yieldbot In the News
RTB’s Fatal Flaw: It’s too slow
From Digiday posted September 23rd, 2014 in Company News
I have some bad news for real-time bidding. The Web is getting faster, and RTB is about to be left behind. Now, 120 milliseconds is becoming too long to make the necessary computations prior to page load that many of today’s systems have been built around.
Visit Site
Yieldbot Hands Publishers A New Way to Leverage Their First-Party Data

From Ad Exchanger posted September 23rd, 2014 in Company News
Yieldbot, whose technology looks at a user’s clickstream and search data in order to determine likeliness to buy, is extending its business to give publishers a new way to monetize their first-party data.
Visit Site
Yieldbot Raises $18 Million to Advance Search-Style Display Buying
From AdAge posted September 23rd, 2014 in Company News
Yieldbot, a New York based ad-tech company that lets advertisers buy display ads via search-style keywords, has raised a $18 million series B round of funding
Visit Site
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
The most amazing thing about the Federal Trade Commission’s workshop about native advertising Wednesday morning is that it happened at all. As Yieldbot CEO Jonathan Mendez noted...
Visit Site
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Publishers in women’s programming verticals such as food and recipes, home and garden, style and health and wellness have found a deep, high volume source of referral traffic from Pinterest.
Visit Site
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Pinterest may have quickly arrived as a major source of traffic to many websites, but those visitors may click on the ads they see there less often than others.
Visit Site
From Our Blog
Yieldbot's First Annual Super Bowl Intent Scorecard
Connect With Us
Where to Find Us
New York City
149 5th Ave.
Third Floor
New York, NY
10010
Boston
1 Clock Tower Place
Suite 330
Maynard, MA
01754
Portland
1033 SE Main St.
Suite #4
Portland, Oregon
97202