Blog
Introducing Pascalog
Posted April 4th, 2012 by admin in Insight
(Shared under Creative Commons Attribution-ShareAlike license: Flikr userTimitrius)
Today, the dev team at Yieldbot is excited to announce plans to open source one of our prized internally developed technologies: Pascalog.
Technology often evolves more in cycles than linearly, with past patterns showing through as more recent innovations are made.
For a while we were doing all of our analytics in Cacsalog, and things were going great. As a Clojure DSL written on top of the Hadoop Cascading API, Cascalog is a brilliant technology for efficiently processing large data sets with very tersely written code.
In fact, we even wrote about those experiences here and here.
But we found ourselves writing things like this:
(<- [!pub !country !region !city !kw !ref !url ?s]<br>
(rv-sq !pub !country !region !city !kw !ref !url ?pv-id ?c)<br>
(c/sum ?c :> ?s))
We thought that there had to be a better way. When we realized that Clojure being a Lisp has its foundations in the 1960’s we immediately realized the next logical step would be an upgrade into the 1970’s.
Wouldn’t we want to write something more like:
program HelloWorld;<br>
begin<br>
writeln('Hello, World!');<br>
end.
And we immediately set upon bringing the best of software development of the 1970’s, Pascal, into the Big Data world of the 2010’s. Pascalog was born. (who couldn’t love a language that wants you to end your programs with a “.”?)
This also fit well with internal discussions we were having at the time lamenting the complexity of managing a Hadoop cluster and the efficiencies that might be gained by combining all the functionality back into one processing environment on a mainframe. That dream is on hold until we find a suitable hardware vendor, but there was certainly no reason to hold Pascalog development back for that.
Data is a readln() Away
In Pascalog we’ve done the heavy lifting. By adapting readln() to be bound to a Cascading Tap, you read data in the way you’ve done since your Turbo Pascal days.
It didn’t take us long to realize that you’d want to save the results of your calculations somewhere, so in a followon version we added the mapping of writeln() to an output Cascading Tap.
Configuring your input and output taps and mapping them to readln() and writeln() is as easy as configuring an INI file.
An upcoming version which should be available shortly will also allow the readln() of one Pascalog program to be mapped to the writeln() of an upstream Pascalog program, allowing you to daisychain your Pascalog programs.
Why Pascal?
We make it sound above like we jumped onto the Pascal bandwagon right away, but in truth we considered several alternatives from the 1970’s.
Of particular interest was the ability to write nested procedures. We’ve grown accustomed to this from our Python development on other parts of the platform and this allows us to migrate between the two worlds more seemlessly (compared to, say, Fortran).
The availability of a goto statement is also a great feature to bail you out if you start getting a little too lost in your control flow. This has become a lost art.
We did consider C, but couldn’t get over the hump of having it named “Clog”.
The Future
We’re furiously looking for a Pascal Meetup group where we can make a live presentation. If you know of one, please let us know!
We have a long list of features in mind to build, but we also want to hear back from the community.
Visit github.com/yieldbot/pascalog to get started! We’re looking forward to the pull requests. If you have live questions there’s usually one of us hanging out on CompuServe under user ID [73217, 55].
Development as Ops Training
Posted April 3rd, 2012 by admin in Insight

It’s become failrly well understood that “Dev” and “Ops” are no longer separate skill sets and are combined into a role called “DevOps”. This role has become one of the hottest and hardest to fill.
At Yieldbot we’ve taken a pretty hardcore approach to putting together Dev and Ops into DevOps that serves us well and should be a great repeatable pattern.
Chef + AWS Consolidated Billing
The underlying philosophy we have is that the development environment should match as closely as possible the production environment. When you’re building an analytics and ad serving product with a worldwide distributed footprint that can be a challenge.
Our first building block is the use of Chef (and on top of that ClusterChef, which is now Ironfan). Using these tools we’ve fully defined each role of the servers in a given region (by defining as a cluster), and all of the services that they run. We coordinate deploys through our Chef server with knife commands, and Chef controls everything from the OS packages that get installed, to the configuration of application settings, to the configuration of DNS names, etc.
The second building block is that every developer at Yieldbot gets their own AWS account as a sandbox. We use the AWS “Consolidated Billing” feature to bring the billing all under our production account. This lets us see a breakdown of everybody’s charges and means we get one single bill to pay.
The last detail is that every developer uses a unique suffix that is used to make resource references unique when global uniqueness is necessary. This is mostly used for resolving S3 bucket names. For any S3 bucket we have in production such as “foo.bar”, the developer will have an equivalent bucket named “foo.bar.<developer>”.
Doing Two Things at Once
With all of that as the status quo, developers are almost always doing two things: developing/testing (the Dev), and learning/practicing how the platform is managed in production (the Ops).
Everyone has their own Chef server, which is interacted with the same way that the production Chef server is. As they deploy the code they are working on into their own working environment, they’re learning/doing exactly what they would do in production.
All of this was put in place over the last year while the developement team was static, during which time we switched from Puppet to Chef.
But the power of this approach really hit home recently as we’ve started to add more people to the team. The first thing a new hire does is go through our process of getting their development environment set up. There’s still bumps along the way, and they get problems and take part in ironing them out. The great thing about this approach though is that each bump is a lesson about how the production environment works and a lesson in problem solving in that environment.
The Differences
Having said all that, there are a couple differences that we’ve put in place between consciously development and production, with the driving force being cost.
The instances are generally sized smaller, since the scale needed for production is much greater. Amazon’s recent addition for support of 64-bit on the m1.small was a great help.
We use several databases (a mix of MongoDB, Redis, and an internally developed DB tech) that are distributed on different machines in production that we collapse together onto a single instance with a special role called “devdb”.
More
We’ll have to have some future blog posts about how we import subsets of production data into development for testing, and the like.
We also use Chef with ClusterChef/Ironfan for managing the lifecycle of our dynamic Hadoop clusters. Yet another good topic for a post all its own.
Have experience with a similar approach or ideas about how to make it even better? We want to hear about it.
Realtime Kills Everything
Posted April 2nd, 2012 by admin in Insight
Our first ad campaigns are live and the results are exciting. The campaign ran on a premium publisher in the women’s lifestyle vertical and beat the publisher’s control group on Click- Through-Rate (CTR) by 77% on the 728 x 90 unit and 194% on the 300 x 250. There were over 1M impressions in the campaign served on this domain over a 2-week period. Yieldbot is now serving the entire campaign.
Most exciting to us are some of the individual results:
- The best performing keyword has a CTR of 1.56%.
- The best creative unit (a 300 x 250) is getting 1.01%
We are running IAB standard banner units. This is not text. This is not rich media.
According to MediaMind the industry average CTR for the campaign vertical is 0.07%
The most matched keyword intent has a CTR of .43%. It also has a CPC of $5.
That math works out to an eCPM of $21.44. That’s pretty exciting stuff. Even more so when you factor in that this campaign is running in what was unsold inventory.
When I shared the results with one of our Board Members he asked me, what at the time I thought was a simple question. “Why are the results so good?” But then, I actually had to think hard about the answer. I had to boil down a year of beta testing and then another year of building a scalable platform into what deserved to be a simple answer.
Realtime.
Realtime was my one word answer. Never before was every page view of intent for this publisher’s visitors captured in realtime - let alone used to make a call to an ad server at that very moment.
Realtime is different. Realtime kills everything before it. As such, Yieldbot is not building ad technology for the web. We are building web technology for ads. Since nothing is more important for advertising success than timing it makes sense that nothing is more valuable for results than realtime.
Realtime was a big buzzword for a while but the hype has died down. That’s good. In the Hype Cycle we’re now somewhere moving from the “Trough of Disillusionment” to the “Slope of Enlightenment.” It is however this ability of the web to react in realtime that makes the future of the medium so exciting.
Twitter of course is the best representative example. Twitter changed everything about media that came before it. Used to be that breaking the story was the big deal Now, even online news seemed stodgy compared to people giving realtime updates that planes have landed on rivers, people being killed and opining on a live show right along with it.
As technology continues to get better at processing the trillions of inputs from millions of people going about their daily lives - doing everything from riding their car to work, buying a pack of chips, surfing the web – the web will respond in realtime. Because of that it will be relevant. The idea of an ad campaign will seem like owning a 32 volumes set of Encyclopedia Britannica. Everything becomes response because the technology is responsive. Calculations need inputs. The web will be measuring just about everything you do and know the moment you are doing it. Nothing will be sold. Everything will be bought.
It’s that realtime pull that creates these new valuations of the media. That new value of the media is what we have been working to create at Yieldbot. That is why these results are so exciting. Best of all, we’re just getting started. We’ve got a bunch of new campaigns about to get underway and we’re only going to get smarter and more relevant. We’ll continue to keep you posted on how it’s going and if you’re running Yieldbot you’ll know yourself. In realtime.
Working at Yieldbot
Posted January 31st, 2012 by admin in Company News
We’re adding more developers to our team and pushing things to the next level. If you like seriously interesting and challenging work in the areas we’re looking for help in, you should be talking to us. You’ll have a single-digit employee number, so you’ll be getting in early and powering us on our way to fulfilling the huge potential we’re sitting on.
What can you expect if you decide to jump in and join us on our mission to make the web experience more relevant? For one thing, no shortage of interesting hard problems to solve, and the latest tools to do it with.
A Great Environment
For our devleopment environment we each have an AWS sandbox that deploys the same code as production, so everyday work is production devops training too, with a Mac for your local dev environment. You’ll have Campfire group chat up all day, and be in the middle of all the important conversations around what we need to do and how we need to do it, from the CEO on down.
The language and tools you use most during the day will depend on what part of the platform you’re focusing on.
A Distributed Realtime Platform
A large part of the core platform is in Python. All of the code around scheduling of tasks and managment of the platform are found here, as well as the key ad serving logic and realtime event processing. You’ll be making use of MongoDB, redis, and ElephantDB. You’ll be solving problems on running the platform distributed across several data centers worldwide. You’ll likely be doing some devops stuff here too, and loving the ease with which Chef lets you get that done.
Bleeding Edge Analytics
If you’re working on our analytics then you are loving the use of Cascalog (a Clojure DSL that runs over the Cascading API on Hadoop). The power-to-lines-of-code ratio here is ridiculous. More than that, you’ll be writing realtime analytics in Storm. That’s not cutting edge, it’s definitely bleeding edge.
Focus on UX
To work on the UI you’re pushing the limits on the latest Javascript UI tools like D3.js and Spine.js. Have you thought about how clean client-side MVC should be done? Spine is it. We’re serious about quality of UX here. If you’re serious about it too, this is where you should be.
An Awesome Team
The team you’ll be joining has been there before. We’ve founded and built successful products, platforms, and companies. We know our industry and what it takes to be successful. And we’re doing it.
The most important thing that keeps us developers here at Yieldbot energized is that we’re building something people want, that’s been clear from the beginning. Our mission to make the web experience more relevant resonates with users, publishers, and advertisers.
If you’re up for the challenge contact us at [email protected]. We have some seriously challenging work you can get started on right away.
How Yieldbot Defines and Harvests Publisher Intent
Posted January 2nd, 2012 by admin in Insight, Analytics, Data
The first two questions we usually get asked by publishers are:
1)What do you mean by “intent”?
2)How do you capture it?
So I thought it was time to blog in a little more detail about what we do on the publisher side.
The following is what we include in our Yieldbot for Publishers User Guide.
Yieldbot for Publishers uses the word “intent” quite a bit in our User Interface. Webster’s dictionary describes intent as a “purpose” and a “state of mind with which an act is done.” Behavioral researchers have also said intent is the answer to “why.” Much like the user queries Search Engines use to understand intent before serving a page, Yieldbot extracts words and phrases to represent the visitor intent of every page view served on your site.
Since Yieldbot’s proxies for visit intent are keywords and phrases the next logical question is how we derive them.
Is Yieldbot a contextual technology? No. Is Yieldbot a semantic technology? No. Does Yieldbot use third-party intender cookies? Absolutely not!
Yieldbot is built on the collection, analytics, mining and organization of massively parallel referrer data and massively serialized session clickstream data. Our technology parses out the keywords from referring URLs – and after a decade of SEO almost every URL is keyword rich - and then diagnoses intent by crunching the data around the three dimensions of every page-view on the site. 1) What page a visitor came from 2) what page a visitor is about to view and 3) what happens when it is viewed.
Those first two dimensions are great pieces of data but it is coupling them with the third dimension that truly makes Yieldbot special.
We give our keyword data values derived from on-page visitor actions and provide the data to Publishers as an entirely new set of analytics that allow them to see their audience and pages in a new way – the keyword level. Additionally, our Yieldbot for Advertisers platform (launching this quarter) makes these intent analytics actionable by using these values for realtime ad match decisioning and optimization.
For example: Does the same intent bounce from one page and not another? Does the intent drive two pages deeper? Does the intent change when it hits a certain page or session depth? How does it change? These are things Yieldbot works to understand because if relevance were only about words, contextual and semantic technology would be enough. Words are not enough. Actions always speak louder.
All of this is automated and all of this is all done on a publisher-by-publisher level because each publisher has unique content and a unique audience. The result is what we call an Intent Graph™ for the site with visitor intent segmented across multiple dimensions of data like bounce rate, pages per visit, return visit rate, geo or temporal.
Here’s an example of analytics on two different intent segments from two different publishers:
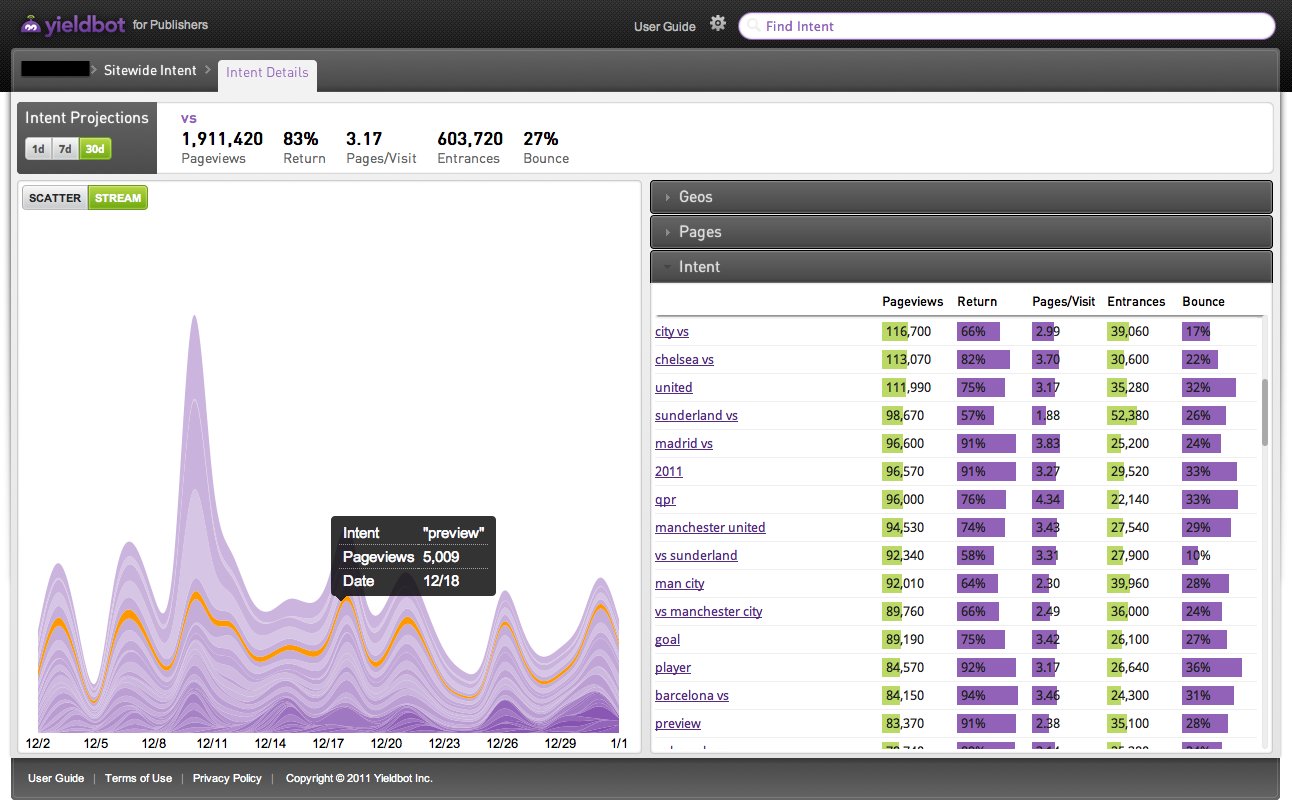
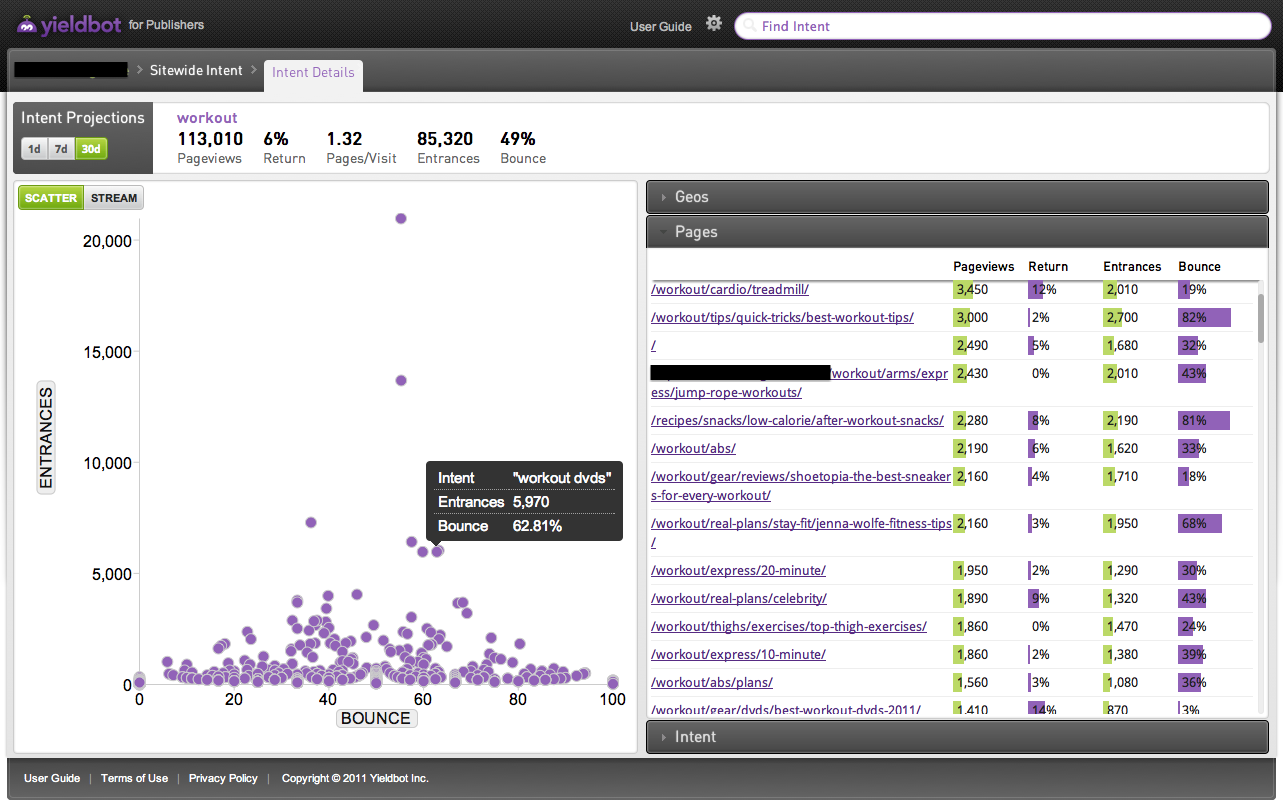
For every (and we mean every) visitor intent and URL we provide data and analytics on the words we see co-occurring with primary intent as well as the pages that intent is arriving at (and the analytics of what happens once it gets there). We also provide performance data on those words and pages.
Yieldbot’s analytics for intent are predictive. This means that the longer Yieldbot is the site the smarter it becomes - both about the intent definitions and how those definitions will manifest into media consumption. And soon all the predictive analytics for the intent definitions will be updated in realtime. This is important because web sites are dynamic “living” entities - always publishing new content, getting new visitors and receiving traffic from new sources. Not to mention people’s interests and intent are always changing.
Browse by Tags
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Follow Us
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
The most amazing thing about the Federal Trade Commission’s workshop about native advertising Wednesday morning is that it happened at all. As Yieldbot CEO Jonathan Mendez noted...
Visit Site
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Publishers in women’s programming verticals such as food and recipes, home and garden, style and health and wellness have found a deep, high volume source of referral traffic from Pinterest.
Visit Site
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Pinterest may have quickly arrived as a major source of traffic to many websites, but those visitors may click on the ads they see there less often than others.
Visit Site
From Our Blog
Marceline's Instruments
Posted June 25th, 2014 by Homer Strong in Clojure, Data, Storm, Analytics
Last December Yieldbot open-sourced Marceline, our Clojure DSL for Storm’s Trident framework. We are excited to release our first major update to Marceline, version 0.2.0. The primary additions in this release are wrappers for Storm’s built-in metrics system. Storm’s metrics API allows topologies to record and emit metrics.
Connect With Us
Where to Find Us
New York City
25 East 21st Street
Eighth Floor
New York, NY
10010
Boston
1 Clock Tower Place
Suite 330
Maynard, MA
01754
San Francisco
811 Sansome St.
San Francisco, CA
94133
Portland
1216 SE Division St.
Portland, Oregon
97202