Blog
Serendipity Is Not An Intent
Posted December 30th, 2011 by admin in Advertising , Discovery

Wired had two amazing pieces on online advertising yesterday and while Felix Salmon’s piece The Future of Online Advertising could be Yieldbot’s manifesto it is the piece Can ‘Serendipity’ Be a Business Model? that deals more directly with our favorite topic, intent.
The piece discusses Jack Dorsey’s views on online advertising and where Twitter is going with it. I had a hard time connecting the dots.
“…all of that following, all of that interest expressed, is intent. It’s a signal that you like certain things,”
Following a user on Twitter is not any kind of intent other than the intent to get future messages from that account. If it’s a signal that you like certain things it’s a signal akin to the weak behavioral data gleaned from site visitations.
Webster’s dictionary describes intent as a “purpose” and a “state of mind with which an act is done.” Intent is about fulfilling a specific goal. Those goals fall into two classes, recovery and discovery.
Dorsey goes on:
When it (Google AdWords) first launched, Dorsey says, “people were somewhat resistant to having these ads in their search results. But I find, and Google has found, that it makes the search results better.”
At the dawn of AdWords I sat with many searchers studying their behavior on the Search Engine Results Pages. What I and others like Gord Hotchkiss who also studied searcher behavior at the time learned, was people were not as much resistant to Search Ads as they were oblivious to them. People did not know they were ads!
Search ads make the results better because they are pull. Your inputs into the system are what pull the ads. So how does this reconcile with the core of Twitters ad products that are promotions? Promos need scale to be effective. Promos are push. Precisely the opposite of Search where the smallest slices of inventory (exact match) produces the highest prices and best ROI.
Twitter is the greatest discovery engine ever created on the web. But discovery can be and not be serendipitous. Sometimes, as Dorsey alludes to, you discover things you had no idea existed. More often, you discover things after you have intent around what you want to discover. This is an important differentiation for Twitter to consider because it’s a different algorithm.
Discovery intent is not an algo about “how do we introduce you to something that would otherwise be difficult for you to find, but something that you probably have a deep interest in?” There is no “introduce” and“probably” in the discovery intent algo. Most importantly, there is no “we.”It’s an algo about “how do you discover what you’re interested in.”
Discovering more about what you’re interested in has always been Twitter’s greatest strength. It leverages both user-defined inputs and the rich content streams where context and realtime matching can occur. Just like Search.
If Twitter wants to build a discovery system for advertising it should look like this.
Using Lucene and Cascalog for Fast Text Processing at Scale
Posted November 6th, 2011 by admin in Cascalog, Lucene
Here at Yieldbot we do a lot of text processing of analytics data. In order to accomplish this in a reasonable amount of time, we use Cascalog, a data processing and querying library for Hadoop; written in Clojure. Since Cascalog is Clojure, you can develop and test queries right inside of the Clojure REPL. This allows you to iteratively develop processing workflows with extreme speed. Because Cascalog queries are just Clojure code, you can access everything Clojure has to offer, without having to implement any domain specific APIs or interfaces for custom processing functions. When combined with Clojure’s awesome Java Interop, you can do quite complex things very simply and succinctly.
Many great Java libraries already exist for text processing, e.g., Lucene, OpenNLP, LingPipe, Stanford NLP. Using Cascalog allows you take advantage of these existing libraries with very little effort, leading to much shorter development cycles.
By way of example, I will show how easy it is to combine Lucene and Cascalog to do some (simple) text processing. You can find the entire code used in the examples over on Github.
Our goal is to tokenize a string of text. This is almost always the first step in doing any sort of text processing, so it’s a good place to start. For our purposes we’ll define a token broadly as a basic unit of language that we’d like to analyze; typically a token is a word. There are many different methods for doing tokenization. Lucene contains many different tokenization routines which I won’t cover in any detail here, but you can read the docs ot learn more. We’ll be using Lucene’s Standard Analyzer, which is a good basic tokenizer. It will lowercase all inputs, remove a basic list of stop words, and is pretty smart about handling punctuation and the like.
First, let’s mock up our Cascalog query. Our inputs are going to be 1-tuples of a string that we would like to break into tokens.
https://gist.github.com/1340591
I won’t waste a ton of time explaining Cascalog’s syntax, since the wiki and docs are already very good at that. What we’re doing here is reading in a text file that contains the strings we’d like to tokenize, one string per line. Each one of these string will be passed into the tokenize-string function, which will emit 1 or more 1-tuples; one for each token generated.
Next let’s write our tokenize-string function. We’ll use a handy feature of Cascalog here called a stateful operation. If looks like this:
https://gist.github.com/1340642
The 0-arity version gets called once per task, at the beginning. We’ll use this to instantiate our Lucene analyzer that will be doing our tokenization. The 1+n-arity passes the result of the 0-arity function as it first parameter, plus any other parameters we define. This is where the actual work will happen. The final 1-arity function is used for clean up.
Next, we’ll create the rest of the utility functions we need to load the Lucene analyzer, get the tokens and emit them back out.
https://gist.github.com/1340665
We make heavy use of Clojure’s awesome Java Interop here to make use of Lucene’s Java API to do the heavy lifting. While this example is very simple, you can take this framework and drop in any number of the different Lucene analyzers available to do much more advanced work with little change to the Cascalog code.
By leaning on Lucene, we get battle hardened, speedy processing without having to write a ton of glue code thanks to Clojure. Since Cascalog code is Clojure code, we don’t have to spend a ton of time switching back and forth between different build and testing environments and a production deploy is just a `lein uberjar` away.
Recent Yieldbot Intent Streams Related to Steve Jobs
Posted October 30th, 2011 by admin in Data
At Yieldbot our focus is on collection, organization and realtime activation of visit intent in publisher content. We do this not as a network but on a publisher-by-publisher basis because of this simple fact; every publisher has a unique audience and unique content. What that means is that even if the keyword is the same across publishers, the intent associated with it varies in each domain.
The original purpose of this post however was not to point out the flaws of networked based keyword buying vs the performance advantage of Yieldbot’s publisher direct model. Nor was the purpose to show you how much we truly understand publisher side intent at the keyword level and how use that intelligence in an automated way to achieve the highest degrees of relevant matching.
The original purpose of the post was to meet the request of a few people that had asked me to share some more data visualization of our Intent Streams™ after we originally shared a few on our recent blog post about our data visualization methods.
It occurred to me the other day that the best representative example over the last month was intent around “Steve Jobs” so below we are sharing our 30-day Intent Streams™ from four publishers.
If you’re new to our streamgraphs the width of the stream is the measure of pageviews of intent associated with the root intent “Steve Jobs.” The other useful data points in these visualizations are the emergence, increases, decreases and elimination of the associated intent over time. As well as how many terms are seen to be associated with the root intent.
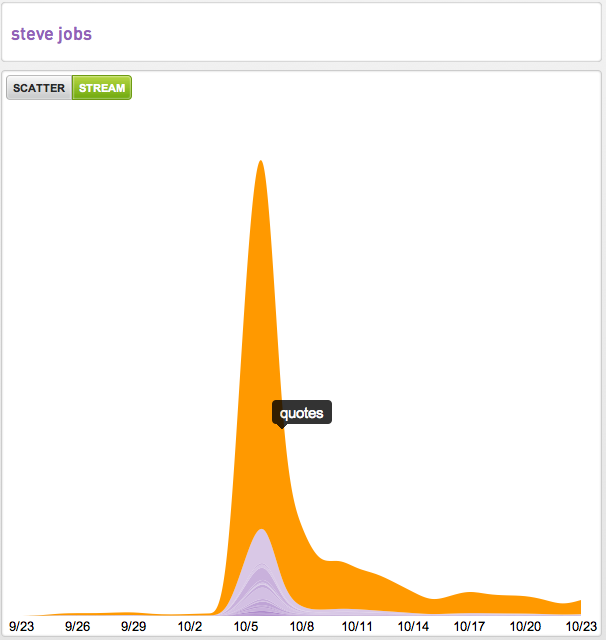
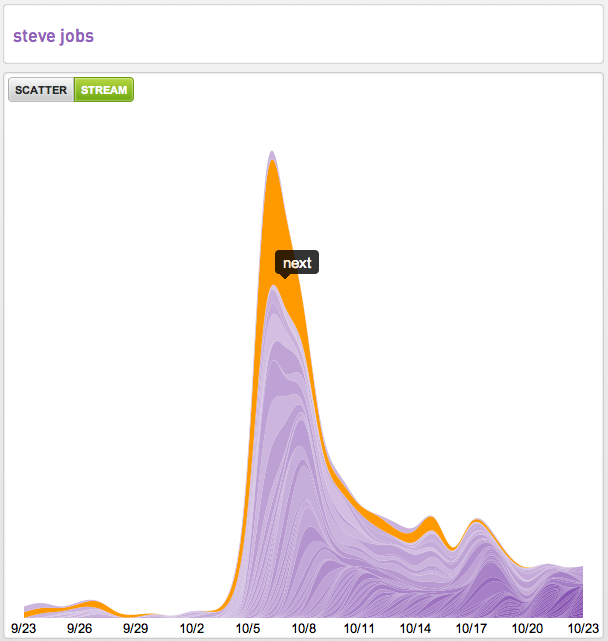
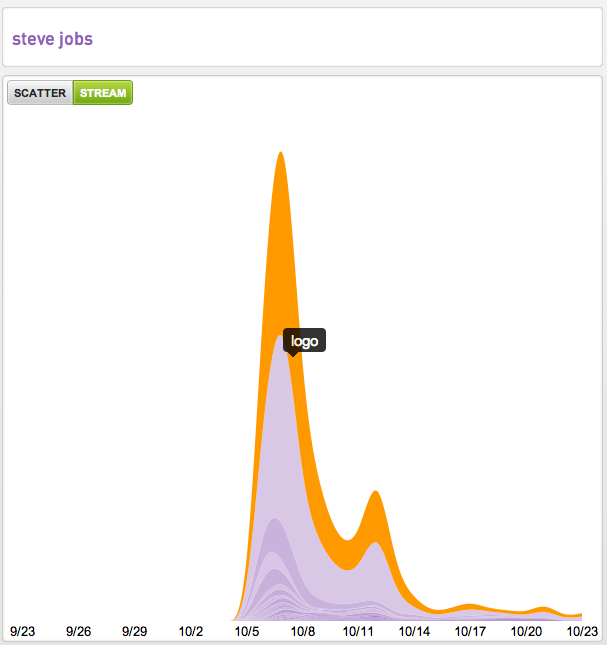
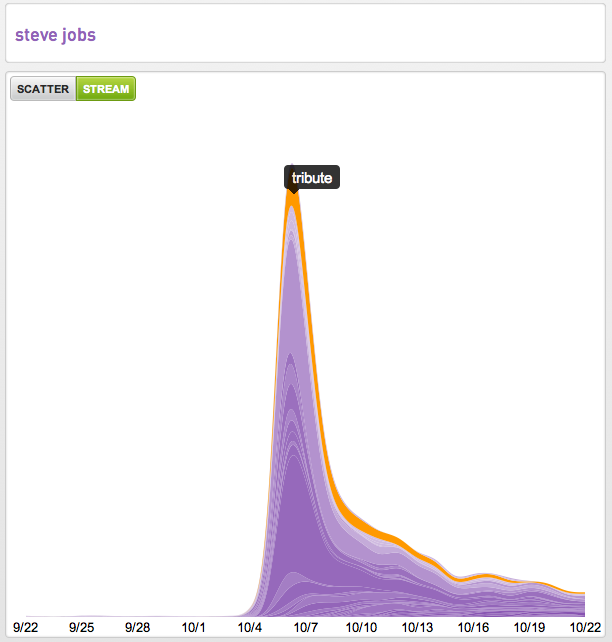
Another way we visualize intent data is across a scatter plot. Here you see the performance of the “Steve Jobs tribute” compared to the other intent related to Steve Jobs looking at the number of entrances (aka landings) on the y-axis and the bounce rate of that intent on the x-axis.
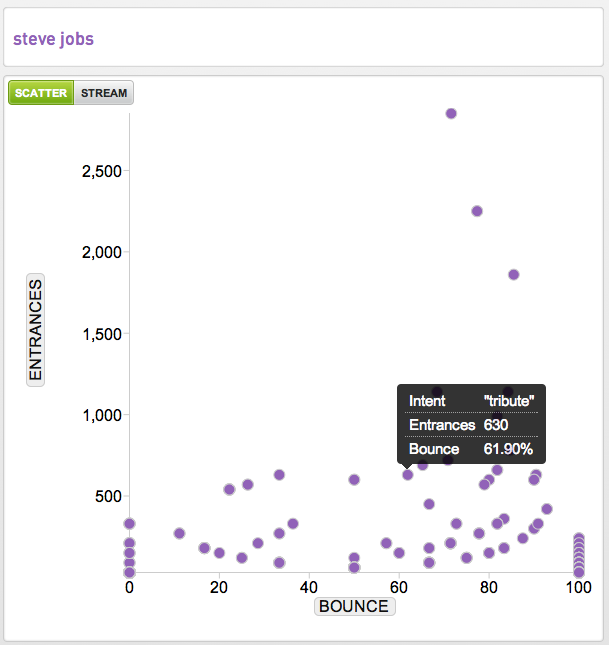
It’s important to note in this scatter plot visualization that the analytics are predictive. We are estimating performance forward over the next 30 days. The four streamgraph visualizations were based entirely on historical data –in their case a 30-day look back as noted on their x-axis.
We hope you find this intent data as interesting as we do.
We Love the Mess of Ad Tech and Wouldn’t Want it Any Other Way
Posted October 24th, 2011 by admin in Content
My introduction to ad tech (roughly): “Ad networks are a mess, you wouldn’t believe what a technical mess the industry is”.
That was in my first meeting with David Cancel (then at Lookery, who since founded Performable, acquired by Hubspot) as I was bouncing an idea off of him that touched on the edges of the ad tech space.
Fast forward 6 months from then (almost exactly two years ago), I got a Twitter DM from David: “Friend is starting a new startup in the ad space. Looking for a CTO and/or help. Any interest?”
About a month later I was the CTO of Yieldbot.
Two years on I can say he was definitely right, ad tech is a mess. Part of it is how it’s evolved and part of it is structural and baked into its nature.
I’ll step it up and say this: ad serving may be the most complex distributed application there is.
The proof is in explaining why.
You Control Almost Nothing
There are so many degrees of freedom it can make your head spin.
You basically have a micro-application running embedded in a variety of site architectures each with their own particular constraints, whose users are distributed around the world running all manner of execution environments (browsers).
When you have your own site or application you still have to deal with (or choose what to support of) the myriad browsers and browser versions, complete with differences in language (javascript) version (or even whether javascript is enabled) and issues like what fonts are available on client systems.
If you are creating a destination site, that keeps your team’s hands full. If you’re serving ads, that’s just a warmup. Because you also don’t control the site architecture that you are embedded in.
You might need to sit behind any number of ad servers the publisher might be running everything through.
You might be in iframes on the page.
You might need to execute code in specific places relative to other ad serving technology also embedded on the page.
Navigation through the site may or may not involve full page refreshes.
But that’s not all…
Distributed Worldwide with Time Constraints
Remember those environments you don’t control? They are the customers’ websites, and they don’t want their users’ UX degraded.
Serve ads, optimize it for relevance, and don’t slow down page load times.
Most websites have some level of focused geographic distribution to their users. Even if it’s as broad as US or even US+Europe.
But for ad serving, your user base is the set of users aggregated across all of the sites using your service. The world is your oyster. And the footprint of what you need to service. Quickly.
But wait! There’s more!
Content Relevant To The User At That Moment
At least if you want to be as cool as Yieldbot.
Look, a CDN serving up a static image can satisfy all of the above if all you want to do is serve the same image to every user across all of your customers’ websites.
Scattershot low value ads picked fairly at random would approximate that level of ease as well.
But there’s no sport (or value) in that!
Our goal here is actually to serve content that is the most relevant to what the user is doing at that particular moment. When done right (we do), everyone wins.
So - simply serve the content that best fits what the user is doing at that moment, where they came from, and what they’ve expressed interest in *right now*, on whatever they happen to be running on, and wherever they happen to be. And make it snappy, would ya?
We Wouldn’t Want It Any Other Way
So, that’s what I signed up for - and I love it. And so does the rest of the Yieldbot team.
We started our first intent-based ad serving on a live site a couple months after coding started and started learning real world lessons immediately. And 20 months later it’s still going.
I’ve always loved to work on systems with complex dynamics, so considering all of the above it’s not that surprising I ended up finding my way to ad tech.
What I love about building Yieldbot technology? All of the above is only half the story. We also do Big Data(tm) analytics for our system to learn the intent of the users coming to our publishers’ sites. We provide them visualizations and data views that teaches them what the intent to their site is. And *then* we enable them to serve ads that make that intent actionable.
#winning
Hacking Display Advertising
Posted October 15th, 2011 by admin in Advertising

Being as passionate as we are about the huge advances in dynamic web languages and event based programming it is tough to love display advertising. Display advertising was never about web programming or data networking. It was nested on the web as a rogue aggregation and delivery mechanism. The ability of display to deliver relevance remains hindered by this disjointed architecture. It is not threaded into site experiences and the realtime goals of the visits on the pages where it resides. This is exactly why we’re hacking it into something else.
Vanilla Sky
In Q2 2007 while most of the industry was living some sort of vanilla sky of Behavioral Targeting one company came in and paid, what at the time seemed to most people way too much money, to own a controlling interest in display. No, I’m not referring to AOL buying TACODA. The company I’m talking about has maintained a focus since day one on hacking what you are interested in at that very moment. Unlike other content aggregatorsit tied its advertising system in the core user experience of its pages and the realtime relevance they delivered. Their stated Display strategy has little to do with cookie matching and everything to do with realtime context and creative optimization with the purpose of “capturing relevant moments.” It is now the most powerful company in Display. That company is of course Google.
Lucid Dreaming
The first lesson here is about the medium itself. This is a different medium and the old media buying and selling template breaks here. Behavioral Targeting may have changed names to the less scary “Audience Buying” but seven years later performance expectations have not been met and it has dragged display into the mud of issues like privacy, ad verification, cookie stuffing and more.
By contrast, Search and email – the most important of the web’s applications - have little use for tracking people across the web, let alone reach and frequency measures. They are the opposite of that. Search (and the web itself) was built by hackers to solve information management and retrieval problems.
The second lesson is that in this medium three pieces of data are valuable – context, timing and performance. The rest is just pipes. Understanding the context of an impression or click at the moment the page is loading and the ability to optimize the message is what the web was built for. It took Search to turn it into a marketing channel but growth (~20% YoY with no end in sight) and the size ($46B in 2013 per eMarketer estimates) of that channel shows how powerful that data is and how helpful understanding it can be to consumers.
Waking Up
The fact that it is referred to as display “advertising” is reason enough to know it’s from another time. This medium kills advertising. Everything on the web is marketing. As Suzie Reider, national director of display sales for Google said recently “display needs to move beyond advertising and into interacting.” Yesterday, Krux CEO Tom Chavez wrote a thoughtful blog post on how it is time for display to move beyond advertising. We agree and we’re walking the walk.
This doesn’t mean that publisher will not show ‘graphical’ units as Google calls them. Of course they will. It doesn’t mean that prime real estate isn’t going to be turned over to these units, they will. We’re headed to a world with fewer messages that will be bigger and more interactive. But if we have learned anything from Search it is that format and size don’t matter when the message is relevant, helpful and useful at that moment.
Billions of Relevant Moments
As long as technology to understand context and timing are progressing as fast as they are (and as places like Betaworks where realtime is the thesis of the new medium value creation the startups are hacking away) there is a bright future. Search has proven that the web is the greatest and most democratic marketing medium ever created. The hackers working with dynamic web languages and event driven programming can unlock an order of magnitude of more relevant moments. There are literally billions of them out there waiting to be captured and created. At Yieldbot we see this scale everyday in the inventory of web publishers and if you’re a hacker and remaking the staid idea of advertising appeals to you we would be interested in speaking with you.
Browse by Tags
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Follow Us
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
The most amazing thing about the Federal Trade Commission’s workshop about native advertising Wednesday morning is that it happened at all. As Yieldbot CEO Jonathan Mendez noted...
Visit Site
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Publishers in women’s programming verticals such as food and recipes, home and garden, style and health and wellness have found a deep, high volume source of referral traffic from Pinterest.
Visit Site
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Pinterest may have quickly arrived as a major source of traffic to many websites, but those visitors may click on the ads they see there less often than others.
Visit Site
From Our Blog
Marceline's Instruments
Posted June 25th, 2014 by Homer Strong in Clojure, Data, Storm, Analytics
Last December Yieldbot open-sourced Marceline, our Clojure DSL for Storm’s Trident framework. We are excited to release our first major update to Marceline, version 0.2.0. The primary additions in this release are wrappers for Storm’s built-in metrics system. Storm’s metrics API allows topologies to record and emit metrics.
Connect With Us
Where to Find Us
New York City
25 East 21st Street
Eighth Floor
New York, NY
10010
Boston
1 Clock Tower Place
Suite 330
Maynard, MA
01754
San Francisco
811 Sansome St.
San Francisco, CA
94133
Portland
1216 SE Division St.
Portland, Oregon
97202