Blog
One Slick Way Yieldbot Uses MongoDB
Posted October 5th, 2011 by admin in Mongo
As a key/value store. Wait, what? Yeah, MongoDB as a key/value store.
Why? Because we were already using Mongo and planned to move some of our data to a key/value store. But we also didn’t want to wait until we made a decision on a specific solution to make the transitions in our code.
First, as if you wouldn’t have guessed, here’s how easy a “Python library for MongoDB as a key/value store” is:
def kv_put(collection, key, value):<br> """key/value put interface into mongo collection"""<br> collection.save({'_id': key, 'v': value}, safe=True)
def kv_get(collection, key):<br> """key/value get interface into mongo collection"""<br> v = collection.find_one({'_id':key})<br> if v:<br> return v['v']
Note: kv_get() returns None if nothing found, so technically this doesn’t gracefully handle the case where you want None to be a possible value.
What was the pain point?
We basically found that we had collections with nightly analytics results that were really big, and whose indexes were really, really big. And the index requirements were going way beyond our 70GB RAM server. We didn’t want to shard our Mongo server because of the cost involved, so instead decided to take a different appraoch. Since this data was read-only results of analytics, where we once had collections that had entries that were multiply indexed, we now have collections that are pages of the old entries in a defined sorted order and are accessed as key/value.
How did the change work out? Great. We still haven’t switched from MongoDB for this data. Still plan to, but in a startup once you address a pain point you move on to the next one.
You definitely can’t argue that MongoDB isn’t flexible.
The Only Chart You Need to Know the Future of Advertising
Posted October 1st, 2011 by admin in Advertising
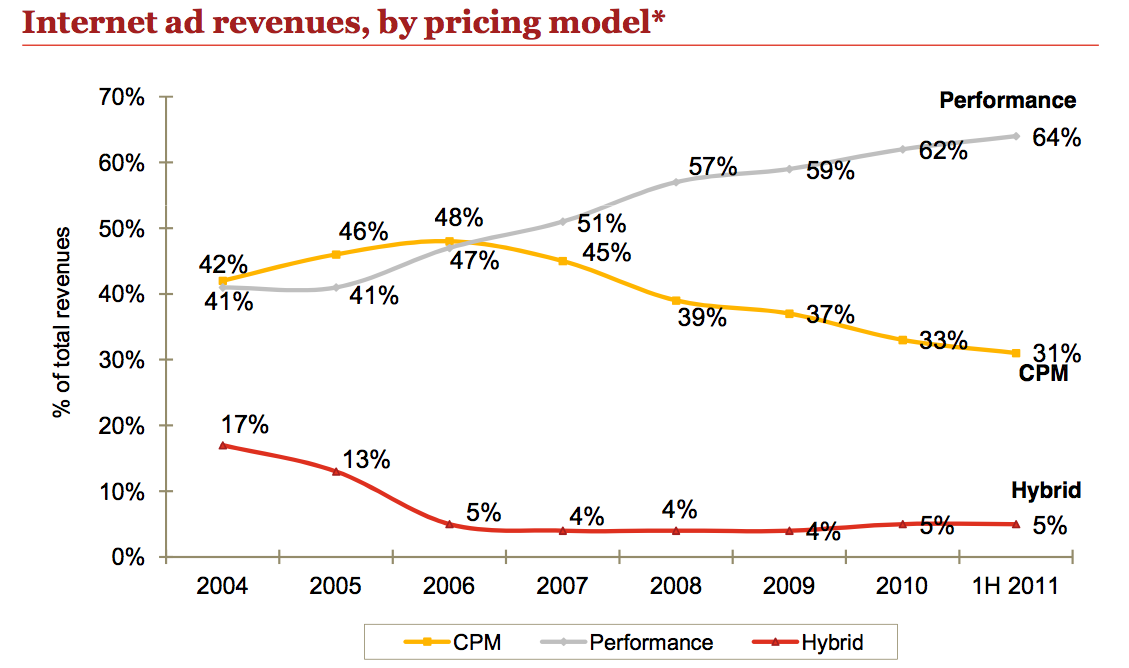
all media is performance media
How Yieldbot uses D3.js + jQuery for Streamgraph Data Visualization and Navigation
Posted September 26th, 2011 by admin in JQuery
One problem we needed to solve early on at Yieldbot was understanding intent trends in the publisher data. This couldn’t just be shallow understanding. We needed to expose multiple data trends at the same time around thresholds and similarity. Our need:
- Allow what we call the “root intent” trend to be apparent.
- Break out the “other words” that are associated with the root intent.
Making this happen in an integrated fashion meant we needed some flexible and powerful tools. We found that d3.js and jQuery UI were the right tools for this job.
Looking through the excellent documentation and examples from d3.js we saw the potential to build exactly the type of visualization we needed. We used a stacked layout with configurable smoothing to allow good visibility into both the overall and individual trends. Smoothing the data made it very easy to follow the individual trends throughout the visualization.
Having settled on this information rich way to visualize the data with d3 we then took the prototype static visualization and made it into a dynamic piece of our interface. It was very important for us that the data be more than just a visualization - we wanted it to be navigation. We wanted the data to be part a tangible and clickable part of the interface. The result was that each of the intent layers is clickable and navigates to another deeper level of data.
Having the core functionality in hand we used the jQuery UI Widget Factory to provide a configurable stateful widget that encapsulates the implementation details behind a consistent API. This makes using the widget very easy. Creating a trend visualization is just a one liner - while the raw power and flexibility is wrapped up and contained in the implementation of the widget.
Here are a few examples of this visualization in action:
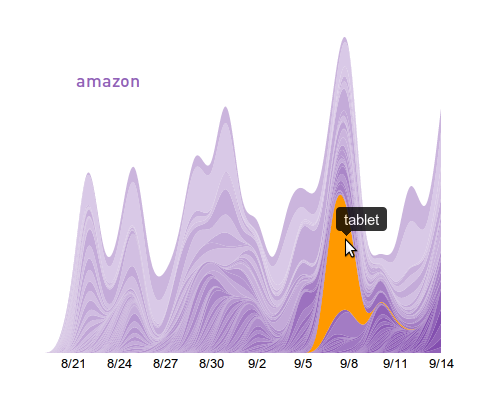
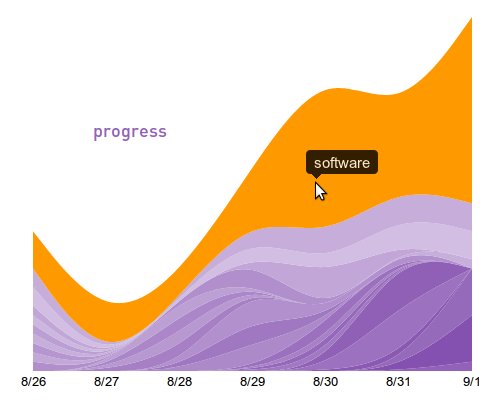
With this reusable widget in hand we could use this trend visualization across our application in numerous places. This provides consistency to our interface that is extremely important UI concern for such a data intensive product.
Our approach to developing innovative data visualizations has been consistently repeatable as we now have 3 additional visualizations in the product and have played around with many more than that. Each time these are the steps we take when creating a new data viz.
Throughout the process the flexibility that d3 provides meant we never bumped into a wall where the framework complexity jumped drastically. It appears that the wall of complexity is still far off in the distance if it exists at all. As our understanding of d3 increased and with the use of prototypes driven by live data we are able to quickly iterate on ideas and design. This flexibility will continue to be one of the many long-term benefits that we’ll get from using d3.
Data visualization plays an important role in our product and we’re excited to keep using it to solved data comprehension problems. Not to mention it really brings the data to life. If you’re interesting in data visualization or this process we’d love to hear your thoughts.
Looking for a Few Good Devs
Posted September 26th, 2011 by admin in Company News
At Yieldbot we’re a small team building incredible technology that’s getting major publishers and advertisers hooked. We’re always looking for the best technical talent to join our development team and work with us on getting to the next level, and as CTO I think it’s only fair that you know what we’re looking for. :-)
What you need to know:
- We’re a small talented team looking to become a bigger talented team.
- We work on tough interesting problems, use cutting-edge “big data” technology, and enjoy winning.
- We’re working on revolutionizing how web advertising works.
- This is gonna be big.
What we need to know:
- You like to solve tough problems and have a history of winning.
- You can code in a few different languages and are expert with one of them.
- That language is Python or you are py-curious.
- You want to make big contributions on a small team and build a valuable business.
Some technology stuff:
- Python’s big here, but we rock Clojure and Javascript too.
- We use Django. Bonus if you know it, but if you don’t it ain’t so hard.
- We wrestle some serious big data, and use Hadoop to do it.
- MongoDB and HBase compete for our love.
- Chef and the Vagrant knifed Puppet and we’ve never been the same
If you’re a fit, dust off your Python and contact us:
yieldbot=[46,13,-19,10,-44,5,60,-4,-2,68,-4,-6,6,-53,-17,6,-2]
”.join(map(chr,map(lambda x:x[0]+x[1],zip(map(ord,str(dir)),yieldbot))))At Yieldbot we’re a small team building incredible technology that’s getting major publishers and advertisers hooked. We’re always looking for the best technical talent to join our development team and work with us on getting to the next level, and as CTO I think it’s only fair that you know what we’re looking for. :-)
Rise of the Publisher Arbitrage Model
Posted September 15th, 2011 by admin in Insight

The business of the web is traffic. Always has been. Always will be. That’s why I was a bit surprised with how much play Rishad Tobaccowala’s quote received last week in the WSJ:
"Most people make money pointing to content, not creating, curating or collecting content."
The original lessons of how to make money on the web got lost because at some point everyone with a web site thought they could go on forever just selling impressions. They didn’t foresee two things:
A) The massive amounts of inventory being unleashed on the web. In the last two years alone Google’s index has gone from 15B pages to 45B pages.
B) The explosive rise of the ad exchange model with its third party cookie matching business that gave advertisers the ability to reach a publisher’s audience off the publisher site and on much cheaper inventory.
Fortunately the more things change on the web the more they stay the same – especially the business models.Traffic arbitrage, the web’s original model, is a more viable model than ever for publishers and likely the only hope to build a sustainable business in the digital age.
The web is literally built around traffic. Here’s what it looks like right now.
From Search to Email to Affiliate the value and monetization of the web occurs in sending and routing these clicks or as Tobaccowala said “pointing out” at a higher return than your cost of acquiring the traffic.
Google of course is the biggest player in the arb business. 75% of the intent Google harvests costs them nothing. They’ve been able to leverage all the intent generation created in other channels like TV that shifts to Google for free. Just take a look at how much TV drives Search. But Google also pays for traffic. Last year they spent over $7.3 Billion or 25% of revenue on what they call TAC (traffic acquisition cost) to get intent. Of course you need this kind of blended model to be successful as Google is with arb.
With the growing (and free) traffic generating intent to publishers it is time they got in this game. Organic Search continues to drive higher percentages of traffic to top publishers (and the Panda update has pushed that even higher). YouTube, Facebook and Twitter are also sending more traffic all the time at no cost to Pubs. The seeds of a huge arb model continue to be sown.
Vivek Shah CEO of Ziff Davis speaking to Ad Exchanger about ‘What Solutions are Still Needed For Today’s Premium, Digital Publisher’ put it this way:
“…you need to invest in technology that can sort through terabytes of data to find true insights into a person’s intent…not just surface “behaviors.”
This speaks directly to the arb model and how it becomes a true revenue engine for publishers. Once you understand the intent that is present on your site you can then quantify its value. Once you quantify the value you can figure what intent you need to get more of, seed that intent with new content and how figure out how much you can spend to drive traffic to it. This is exactly the model we’ve been working with publishers - using Yieldbot to qualify and quantify the intent on their sites.
So the future of the web looks a lot like the past. There will be marketing levers and technologies that optimize what traffic you drive in and there will be marketing technologies that optimizes where and at what value that same traffic goes out. Everything else you will do in your business will support those value creation events. Yieldbot just wanted to “point out” that for publishers.
Browse by Tags
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Follow Us
Yieldbot In the News
Much Ado About Native Ads
From Digiday posted December 5th, 2013 in Company News
The most amazing thing about the Federal Trade Commission’s workshop about native advertising Wednesday morning is that it happened at all. As Yieldbot CEO Jonathan Mendez noted...
Visit Site
Pinterest Dominates Social Referrals, But Facebook Drives Higher Performance [Study]
From Marketing Land posted October 3rd, 2013 in Company News
Publishers in women’s programming verticals such as food and recipes, home and garden, style and health and wellness have found a deep, high volume source of referral traffic from Pinterest.
Visit Site
Pinterest Sends Your Site More Traffic, Study Says, but Maybe Not the Kind You Want
From Ad Age posted October 3rd, 2013 in Company News
Pinterest may have quickly arrived as a major source of traffic to many websites, but those visitors may click on the ads they see there less often than others.
Visit Site
From Our Blog
Marceline's Instruments
Posted June 25th, 2014 by Homer Strong in Clojure, Data, Storm, Analytics
Last December Yieldbot open-sourced Marceline, our Clojure DSL for Storm’s Trident framework. We are excited to release our first major update to Marceline, version 0.2.0. The primary additions in this release are wrappers for Storm’s built-in metrics system. Storm’s metrics API allows topologies to record and emit metrics.
Connect With Us
Where to Find Us
New York City
25 East 21st Street
Eighth Floor
New York, NY
10010
Boston
1 Clock Tower Place
Suite 330
Maynard, MA
01754
San Francisco
811 Sansome St.
San Francisco, CA
94133
Portland
1216 SE Division St.
Portland, Oregon
97202